From REST Calls to Event Streams: How I Stopped Fighting My Microservices and Started Designing Them
Most developers reach for HTTP and call it microservices. But request-response, message queues, and event streaming are not the same thing they carry different guarantees, different failure modes, and different operational costs. Here's how to actually tell them apart, and when to use which.
I used to think I was building a microservices architecture.
Turns out, I was building a monolith with extra network calls.
That realization hit me somewhere around the third time a service timeout caused a cascade failure that took down three unrelated features in my system. Nothing like a 3 AM incident to make you actually think about architecture.
When you're new to distributed systems, the instinct is to replace function calls with HTTP calls. Service A needs data from Service B? Easy just call the endpoint. It feels clean. It feels like microservices. But what you've actually done is introduce all the failure modes of a distributed system while keeping all the tight coupling of a monolith. Worst of both worlds.
The more I worked on my microservices project, the more I kept running into the same class of problems ,not bugs, not logic errors, but architectural friction. Services waiting on each other. One slow service blocking everything downstream. A retry storm that made things worse. That's when I started going deeper into how communication between services actually works, and why the default approach (just call the REST endpoint) doesn't scale in certain contexts.
This article is about what I learned. Specifically, the difference between request-response, message queues, and event streaming. When to use which. And what nobody tells you about the trade-offs.
How We All Start: The Request-Response World
HTTP is the first tool we reach for. And honestly, for a lot of things, it's the right one.
Request-response is intuitive: you ask, you get an answer. It maps directly to how we think about operations "I need user data, so I call the user service." The contract is simple, the debugging is straightforward, and every developer on your team already understands HTTP.
But request-response is synchronous and tightly coupled by design. When Service A calls Service B:
- Service A is blocked waiting for B's response
- If B is slow, A is slow
- If B is down, A fails
- If B changes its API contract, A breaks
At small scale, this is fine. At production scale, with dozens of services, this becomes a reliability nightmare. Every call is a point of failure. Every dependency is a chain that can break.
The deeper issue isn't the HTTP protocol itself it's the temporal coupling. The caller and the receiver must both be alive, responsive, and available at the exact same moment. That's a strong assumption in a distributed system.
This is the problem that message queues and event systems were built to solve.

The Three Paradigms You Need to Understand
Before you can make smart architecture decisions, you need to understand the three fundamental ways services communicate. These aren't just different tools — they represent completely different mental models of how systems interact.
1. Request-Response (Synchronous)
You know this one. REST APIs, gRPC calls, database queries. The caller blocks and waits. The receiver must be available.
Use it when: You need an immediate answer to continue processing. User authentication. Real-time lookups. Anything where the response is the point of the operation.
Avoid it when: The operation is long-running, the receiver is unreliable, or the caller genuinely doesn't need to wait.
2. Queue-Based Messaging (Async Commands)
A producer puts a message in a queue. A consumer picks it up and processes it — at its own pace, on its own schedule. The producer has moved on.
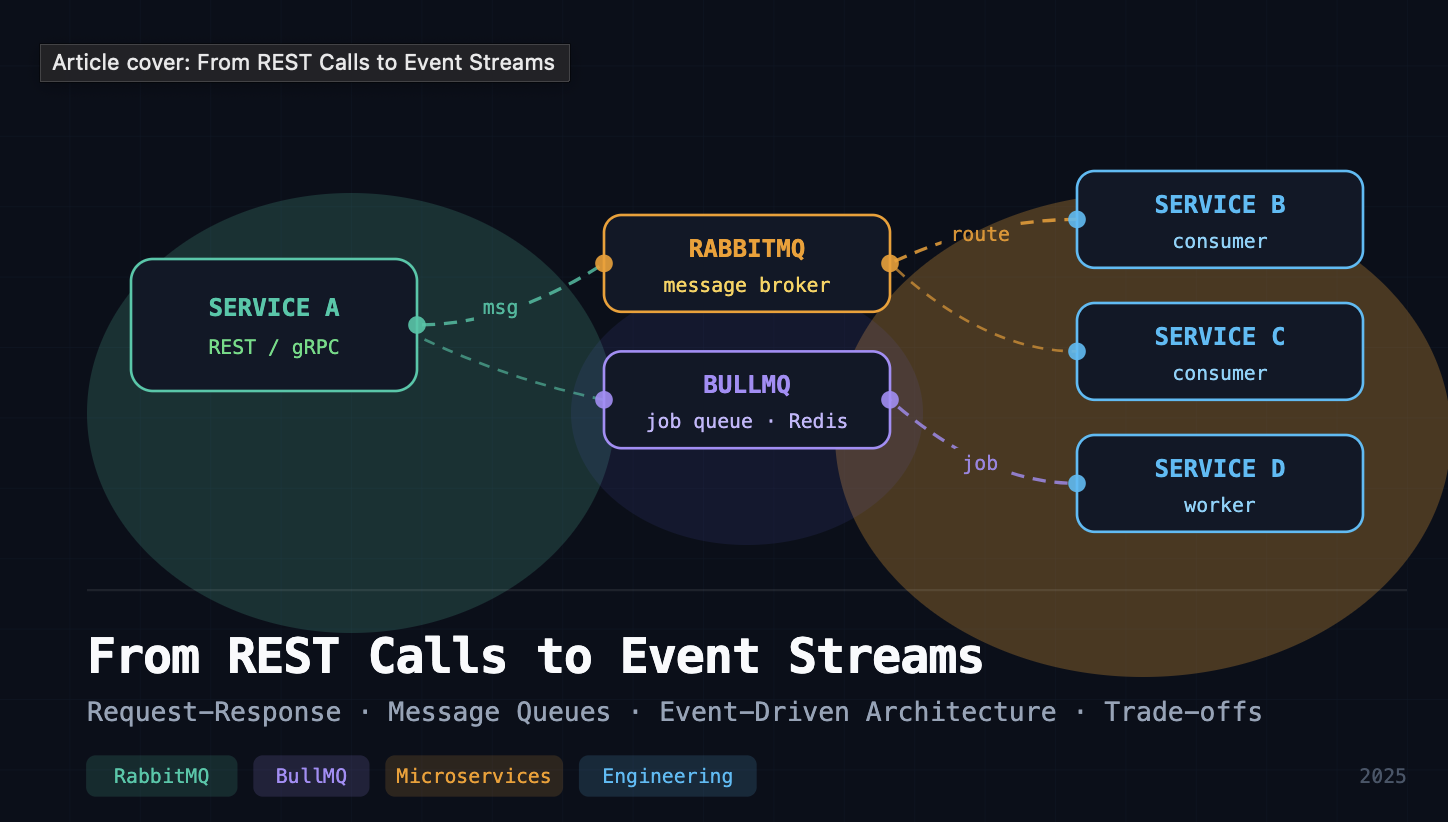
This is where RabbitMQ lives. A message in a queue is a command — "do this thing." It's point-to-point: one message, one consumer. The queue guarantees delivery, handles retries, and acts as a buffer absorbing traffic spikes.
In my project, I use RabbitMQ for service-to-service work distribution. One service needs another to process something? Drop a message in the queue. If the consumer is down, the message waits. No cascade failure.
BullMQ is another tool I use, but it operates in a different space. It's a Redis-backed job queue — purpose-built for background job processing within a service boundary. Think scheduled jobs, retry logic, delayed execution. It's not a service-to-service communication tool; it's a job orchestration layer.
Use queue-based messaging when: You have work that can be processed asynchronously, you need load leveling across multiple consumers, or you want to decouple the pace of production from the pace of consumption.
3. Event Streaming (Async Events)
This is the paradigm most developers reach for last, but arguably the most powerful for complex systems.
An event stream (Kafka being the canonical example) is an append-only, distributed log. Events are facts about things that happened: order.placed, payment.processed, user.registered. They aren't commands — they don't tell anyone to do anything. They just record what happened.
Any number of consumers can read the same event, independently, at their own pace. The log is persistent and replayable — meaning a new service can come online and read the entire history. This is the foundation of event sourcing and CQRS (Command Query Responsibility Segregation) patterns.
Wait — Messages and Events Are NOT the Same Thing
This is the most common confusion I see, and it's worth being very explicit about.
| | Message | Event |
|---|---|---|
| Semantics | Command: "do this" | Fact: "this happened" |
| Direction | Sent to a specific consumer | Broadcast to anyone listening |
| Coupling | Producer knows a consumer exists | Producer is unaware of consumers |
| Pattern | Point-to-point | Publish-subscribe |
| Example | send-welcome-email command | user.registered event |
When you send a message, you're saying "hey, you — do this." The producer is aware that a consumer exists and has a contract with it.
When you emit an event, you're saying "this happened — whoever cares, do what you need to." The publisher has zero knowledge of what downstream systems will react, or how many of them there are.
This distinction has real architectural consequences. Message-based systems are easier to reason about — explicit contracts, explicit consumers. Event-driven systems are more flexible and scalable — new consumers can subscribe without any changes to the publisher — but they're harder to trace and debug.

How I'm Actually Using This in My Project
Theory is useful. Real architectural decisions are more interesting.
In the microservices project I'm building, I'm using two different async tools for two different problems — and the distinction matters a lot.
RabbitMQ: Service-to-Service Messaging
RabbitMQ handles cross-service communication that can't afford to be synchronous. When one service needs another to perform work — but doesn't need to wait for the result — a message goes into a RabbitMQ exchange, gets routed to the right queue, and the consumer picks it up.
Key decisions I made here:
Exchange types matter. RabbitMQ's routing model (direct, topic, fanout, headers) gives you precise control over how messages flow. A direct exchange routes by exact key — good for explicit commands. A topic exchange routes by pattern — closer to event-like behavior where multiple queues can match one routing key. I use both, depending on whether I'm sending a command or broadcasting work to multiple consumers.
Dead-letter queues are not optional. Every queue in production needs a dead-letter exchange configured. If a consumer can't process a message after retries — maybe the data is malformed, maybe there's a bug — the message needs to land somewhere safe for inspection, not disappear silently. This is the difference between observable async systems and black holes.
Prefetch count is a tuning lever most developers ignore. RabbitMQ's prefetch setting controls how many unacknowledged messages a consumer can hold at once. Set it too high and a slow consumer accumulates a backlog it can't process. Set it too low and you're underutilizing your consumers. Get this wrong and your "decoupled" system just moved the bottleneck.
BullMQ: Background Job Processing
BullMQ is a different kind of tool for a different kind of problem. It's Redis-backed, which means it's fast and optimized for job state management — not cross-service messaging.
I use BullMQ for things like: scheduled tasks, retry logic with exponential backoff, delayed jobs, and jobs with priority queues. The value proposition here is the job lifecycle management — BullMQ tracks each job through waiting, active, completed, and failed states with built-in retry support.
Where RabbitMQ is about routing messages between services, BullMQ is about managing the execution of background work within a service boundary. They solve adjacent but distinct problems. Conflating them leads to over-engineering.
The overall architecture looks like this:

Which One Should You Actually Use?
Here's the decision framework I use. Not a flowchart — a set of questions:
1. Does the caller need the result to continue? If yes — request-response. Don't complicate it.
2. Is the work fire-and-forget, or does it need guaranteed delivery? Fire-and-forget with guaranteed delivery = queue-based messaging.
3. Will multiple downstream systems react to the same thing? If yes — events, not messages. You want publishers decoupled from an unknown set of subscribers.
4. Do you need to replay history or audit what happened? Event streaming. A queue destroys messages after consumption. A log persists them.
5. Is this within a single service or crossing service boundaries? Within a service, BullMQ-style job queues. Across services, RabbitMQ or an event broker.
| Criterion | Request-Response | Queue Messaging | Event Streaming | |---|---|---|---| | Latency sensitivity | Best | Medium | High | | Decoupling | None | Partial | Full | | Fan-out (1 to many) | No | No | Yes | | Message ordering | Guaranteed | Queue-level | Partition-level | | Durability | No | Yes | Yes | | Replayability | No | No | Yes | | Operational complexity | Low | Medium | High |
The Trade-offs Nobody Talks About
Async systems feel like magic until they don't. Here's what actually hurts in production:
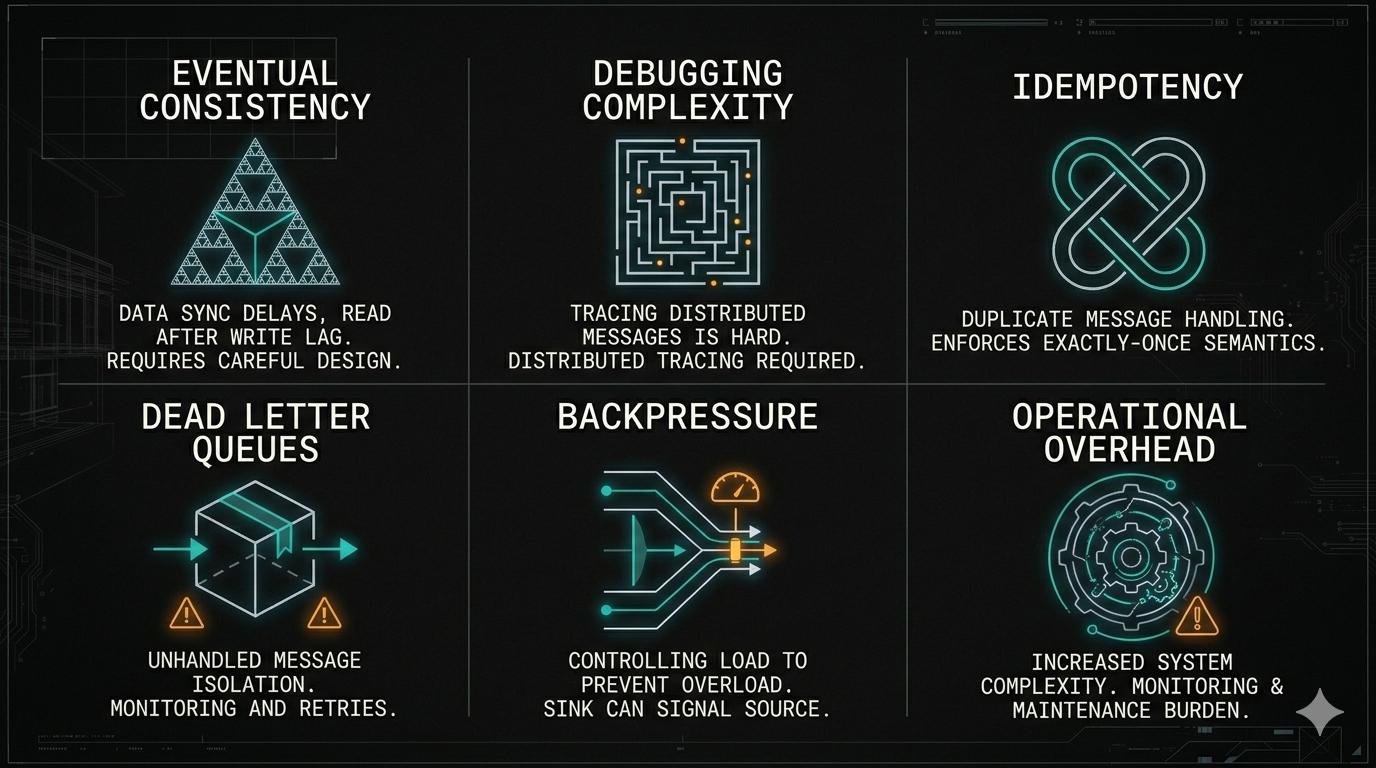
Eventual consistency. When you move to async, you give up synchronous consistency. The order service says "placed" but the inventory service hasn't processed the message yet. Your system is eventually consistent — which means your UI, your error handling, and your user expectations all need to account for this. This is not a small change. It's a fundamental shift in how your system behaves.
Debugging is exponentially harder. In synchronous systems, a stack trace tells you everything. In async systems, the consumer that failed is disconnected from the producer that sent the message. You need distributed tracing (OpenTelemetry, Jaeger), correlation IDs on every message, and a centralized logging strategy — before you need them, not after.
Idempotency is not optional. Messages get re-delivered. Network blips, consumer crashes, and retries mean your consumer will process the same message more than once. Every consumer must be idempotent — running it twice produces the same result as running it once. If you skip this, you'll have duplicate emails, duplicate charges, and corrupted state.
Dead-letter queues need monitoring. A dead-letter queue that nobody watches is just a slow data loss mechanism. If messages are landing in your DLQ, that's a silent production error. Alert on it.
Backpressure is a real problem. If producers outpace consumers, your queue grows unboundedly. You need consumer scaling strategies, rate limiting on producers, or circuit breakers — ideally all three.
Engineering Thinking vs Developer Thinking
Here's the honest conclusion from everything I've worked through:
A developer picks a tool because it's popular, or because the tutorial used it, or because the team already knows it. An engineer picks a tool because they understand the guarantees it provides, the failure modes it introduces, and the operational burden it carries.
RabbitMQ isn't "the messaging tool." It's a broker with specific routing semantics, acknowledgment models, and durability guarantees. BullMQ isn't "the background job tool." It's a Redis-backed state machine for job lifecycle management. Kafka isn't "the Kafka thing." It's an append-only distributed log with replayable partitions and consumer group offsets.
These are different tools with different contracts. Using them interchangeably because they all sound like "async" is how you end up with architectures that technically work but operationally collapse.
The moment I stopped thinking about messaging as a way to avoid HTTP calls, and started thinking about it as a set of communication contracts with specific guarantees — that's when my architecture decisions got cleaner. Not perfect. Cleaner.
That's the shift worth making.
Subscribe to Updates
Get notified about new projects and articles.
Comments
Loading comments...