Why Your AI Background Job Is Probably Lying to You
Most AI processing pipelines look like they work until one crash reveals they have been silently duplicating data, swallowing failures, and pretending retries are safe. This is the full story of breaking a production pipeline and rebuilding it the right way.
I built a pipeline that processed PDF documents for an AI system. It extracted text,
generated embeddings, and stored everything in a vector database. The endpoint returned
202 Accepted. The logs looked clean. The job status showed completed.
For weeks, I thought it worked.
Then a worker crashed mid-job, and I watched it restart and silently insert every chunk into MongoDB twice. The vector database got duplicate vectors. Semantic search started returning the same result multiple times. And because the error happened inside a background worker, not in the request thread, no alert fired, no 500 was logged, and the user never knew.
That was the moment I realized I had built something that looked like a production system but was actually one crash away from corrupted state at all times.
This post is about what I found, what I fixed, and why most AI workload pipelines have the same problems whether they process PDFs, images, audio, or any other content that requires expensive compute.
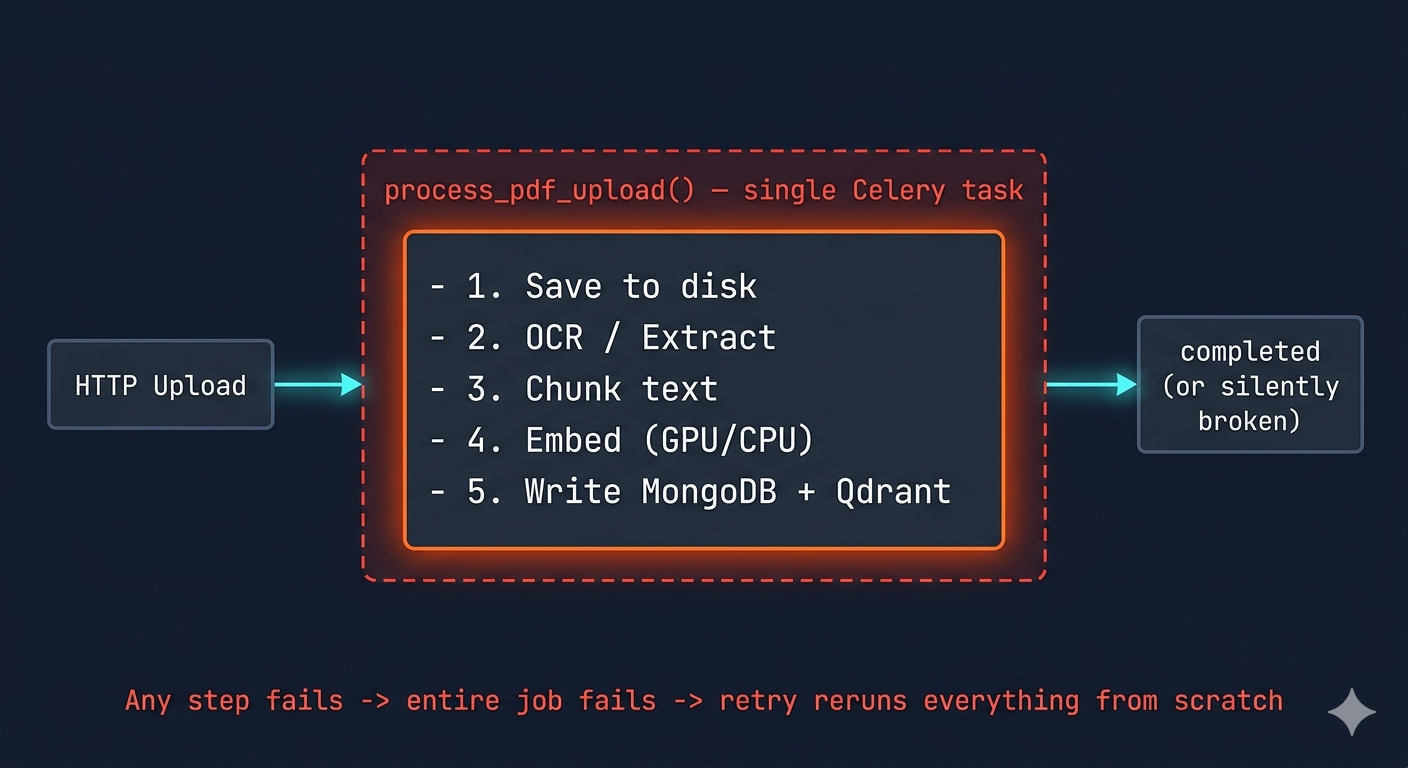
The Naive Approach
Every AI processing pipeline starts the same way. You have a user-facing action, upload a document, submit an audio file, kick off a report generation, and you know it will take more than a few seconds. So you reach for a background worker.
In Python, that usually means Celery. In Node, it might be BullMQ or a Lambda. In Go, a goroutine with a work queue. The implementation details differ, but the first version almost always looks something like this:
@shared_task(name="process_pdf")
def process_pdf(file_path, pdf_id):
text = extract_text(file_path) # OCR => can take minutes
chunks = split_into_chunks(text)
embeddings = generate_embeddings(chunks) # expensive model inference
save_to_mongo(chunks)
save_to_qdrant(embeddings)
mark_completed(pdf_id)This runs. It passes your tests. The endpoint returns a job ID. The frontend polls for status. Everything looks fine.
The problem is not what this code does when it works. The problem is what it does when anything goes wrong, and in production, something always goes wrong.
Eight Problems Hidden Inside That Innocent Function
When I started auditing my pipeline seriously, I found eight distinct failure modes. None of them required unusual conditions. They all happen under normal production load.
1. Retries recreate the data they already wrote. If MongoDB writes succeed but Qdrant fails, the task raises an exception. Celery retries it. But MongoDB already has those documents. The retry inserts them again, now you have duplicates.
2. The file is deleted before the retry can use it.
The finally block of my task called os.unlink(file_path). That runs after every attempt,
including failed ones. The retry tries to open a file that no longer exists.
3. Random IDs make retries poison pills. My task generated a UUID for each Qdrant vector point at insertion time. Retry runs the same chunk but generates a new UUID. Both vectors live in the database. Search quality degrades.
4. One failure reruns everything. OCR on a 200-page PDF can take four minutes. If the Qdrant write fails at the very end, the retry goes all the way back to OCR. Four minutes of compute, wasted, every single time.
5. The task message is acknowledged before execution. Celery's default is to tell the broker "got it, working on it" as soon as it picks up the task, before it runs a single line of code. If the worker crashes mid-execution, the message is gone. The job simply disappears.
6. Cancellation does not cancel anything.
Sending SIGTERM to a Celery worker signals a graceful shutdown: finish the current task,
then stop. The task kept running. The user who clicked "cancel" saw the status update
but the worker processed the entire document anyway.
7. No time limits means stuck workers block everyone. A corrupt PDF caused my OCR library to enter an infinite loop. That worker was occupied for six hours before I noticed. Every other document queued behind it waited.
8. Partial writes leave orphaned data. When a task fails after writing to MongoDB but before writing to Qdrant, those MongoDB documents stay there, disconnected from any vector, invisible to search, taking up space. There is no cleanup because the task never reached the cleanup code.
Why a Message Broker Changes Everything
The moment you put a broker between your API server and your workers, you gain a guarantee that feels simple but has enormous consequences: a task message is not removed from the queue until the worker explicitly says it finished.
This is controlled by a setting called acks_late. The default in Celery is
to acknowledge the message immediately on receipt, before any code runs. That means
a worker crash mid-task silently swallows the job. With acks_late=True, the message
stays in the queue until the task either succeeds or explicitly fails. Combined with
reject_on_worker_lost=True, a crashed worker returns the message to the queue
automatically.
@shared_task(
bind=True,
acks_late=True,
reject_on_worker_lost=True,
max_retries=3,
)
def process_document(self, ...):
...Beyond reliability, the broker gives you something else: decoupling. Your API server can run on one machine, your workers on another, and your broker on a third. In distributed deployments, multiple servers, containers across ECS or Kubernetes,they all connect to the same broker. When the API sends a task, the broker holds it. Any available worker picks it up. This is how you scale horizontally without changing a line of application code.
Revocation works through this same channel. When you call celery.control.revoke(task_id, terminate=True, signal="SIGKILL"), that command travels through the broker to the worker
running the task. The worker receives it and kills the subprocess. This only works when the
worker has a process pool, not when running in solo mode, where the main process is
blocked executing the task and cannot read from the broker at the same time.
That was one of my bugs. I was running with --pool=solo during development (a common
workaround for macOS forking issues with PyTorch), and every revoke call I sent was
sitting in the broker, unread, while the worker finished the entire job.
Idempotency Is Not Optional
Idempotency means running the same operation twice produces the same result as running it once. It sounds academic until you are in production and a worker crashes after writing to one database but before writing to another. Your retry runs the whole thing again. Now you have twice the data in the first database and the correct amount in the second.
For AI pipelines specifically, this is a serious problem. A document with 500 chunks, each with a vector embedding, inserted twice into a vector database will return every result twice during search. Your reranking might handle it, your deduplication might catch it, but the right answer is: it should never have been inserted twice in the first place.
The root cause is almost always random ID generation:
# Every retry generates a new ID, so it's always a new document
point_id = str(uuid.uuid4()) # ab3f... on first run, 9c12... on retryThe fix is deterministic IDs — the same inputs always produce the same output:
import hashlib, uuid
def stable_id(pdf_id: str, chunk_index: int) -> str:
digest = hashlib.sha256(f"{pdf_id}_{chunk_index}".encode()).digest()
return str(uuid.UUID(bytes=digest[:16]))Now chunk_0 of document abc123 always gets the same UUID. Qdrant's upsert operation
(insert or replace) becomes naturally idempotent, a retry replaces the existing vector
with an identical one. No duplicate.
For MongoDB, the same principle applies. Assign the document _id deterministically,
use ordered=False on batch inserts, and catch BulkWriteError gracefully:
prepared_doc["_id"] = stable_id(pdf_id, chunk_index)
try:
collection.insert_many(docs, ordered=False)
except BulkWriteError:
pass # already exists from a previous attempt, that is fineThe documents are identical. The operation is safe. The retry becomes a no-op for every step that already succeeded.
Pair this with a unique compound index on (pdf_id, chunk_index) at the database level,
and you have a second enforcement layer that catches any code path that might bypass
your application-level check.
Breaking the Monolith Into a Workflow
Once you accept that individual stages should fail and retry independently, the natural
architecture is a chain of smaller tasks rather than one large one. In Celery this is
called a chain , a sequence where each task in the list runs after the previous one completes.
from celery import chain
pipeline = chain(
extract_text_task.si(job_id=job_id, pdf_id=pdf_id),
embed_chunks_task.si(job_id=job_id, pdf_id=pdf_id),
store_vectors_task.si(job_id=job_id, pdf_id=pdf_id),
)
pipeline.apply_async()The .si() notation creates an immutable signature — each task receives only the
arguments you specify, not the return value of the previous task. This is deliberate.
If OCR produces 500 chunks, you do not want to pass those 500 chunks through Redis
(your result backend). You want to store them somewhere durable, S3, a database,
and have the next task read from there.
This intermediate state storage solves two problems simultaneously. First, it keeps your broker and result backend lean. Second, it means each task can be resumed independently. If embedding fails and retries, it downloads the chunks from S3 that OCR already produced. OCR never runs again.
The workflow state itself lives in a tracking collection, I called it DocumentProcessing:
{
"job_id": "uuid",
"extract_status": "completed",
"extract_chunks_s3_key": "processing/uuid/chunks.json",
"embed_status": "failed",
"embeddings_s3_key": null,
"store_status": "pending"
}Every task checks its own status field first. If it says completed, the task returns
immediately. This is the idempotency gate, and it means re-submitting a completed
pipeline is safe. It means a task can be retried without fear of the previous successful
work being repeated. It means a crashed worker coming back up can pick up exactly
where the pipeline left off.
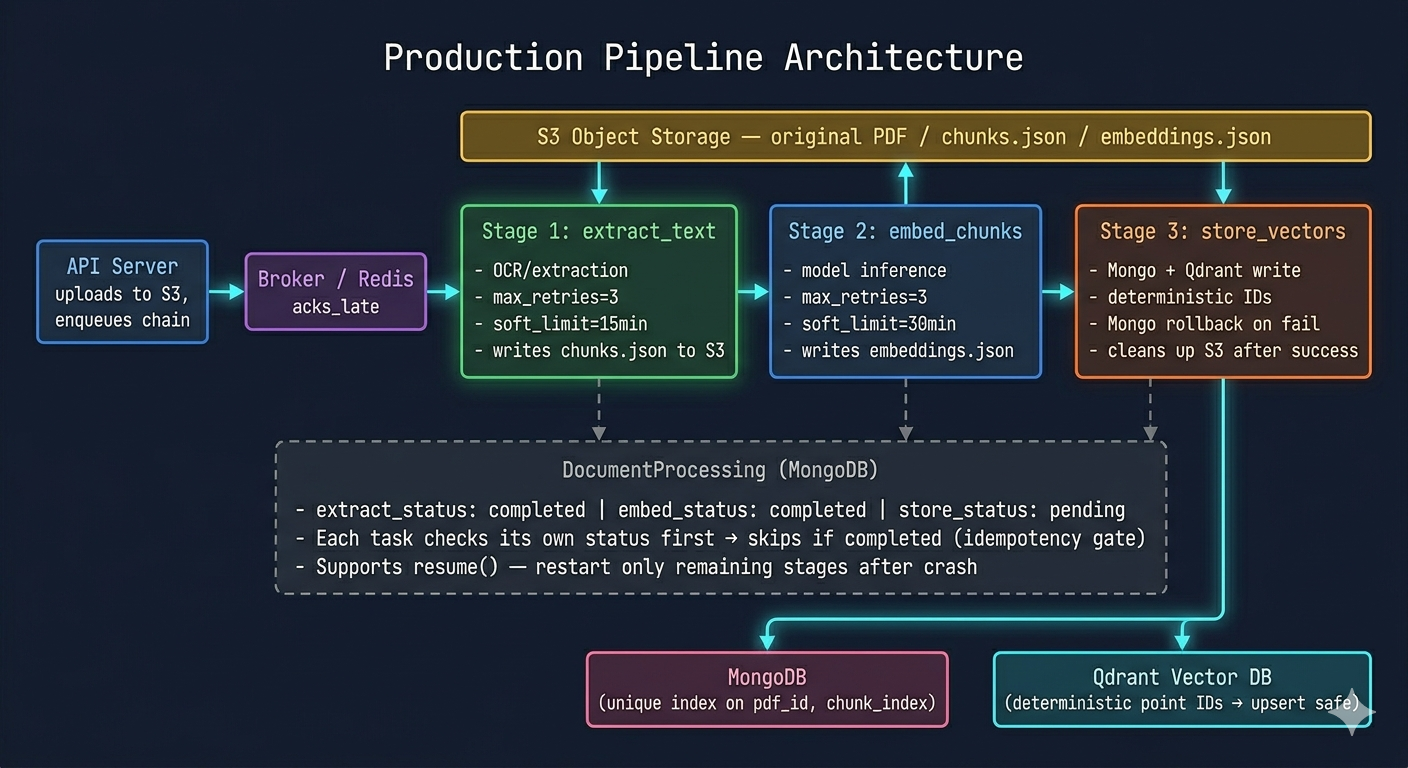
The Problem Nobody Talks About: Cross-Database Consistency
Most AI systems write to at least two stores. A document database holds the raw text and metadata. A vector database holds the embeddings for semantic search. These two stores have no shared transaction. If you write to MongoDB and then Qdrant fails, you have a MongoDB document with no corresponding vector. That document is invisible to search but consuming storage and appearing in metadata queries.
The straightforward approach is a rollback on failure:
try:
for batch in chunks(points, size=100):
qdrant.upsert_batch(batch)
except Exception as qdrant_error:
# Qdrant failed — undo the MongoDB writes
mongo.delete_many({"pdf_id": pdf_id})
raise qdrant_errorWith deterministic IDs, this rollback is safe to do on every retry. The next attempt
re-inserts MongoDB documents (no-ops due to existing _id) and re-upserts Qdrant
vectors (replacing identical data). The system converges to a consistent state
regardless of how many times it runs.
This is what eventual consistency with strong idempotency guarantees looks like in practice. You cannot have a distributed transaction across MongoDB and Qdrant. But you can design your writes so that partial completion is detectable and correctable on the next attempt.
The S3 cleanup timing is the final piece. In my original code, the finally block
deleted the uploaded PDF file from storage unconditionally. If the job failed and
retried, the file was gone. The fix: delete S3 files only after both
mark_completed calls succeed — never in a finally block, never on failure.
# Correct order:
PDFJobService.mark_completed(job_id, ...) # 1. mark job done
PDFUploadService.mark_completed(pdf_id) # 2. mark upload done
S3Service.delete_files([pdf_key, chunks_key, embeddings_key]) # 3. then clean upIf the process crashes between steps 1 and 3, the S3 files survive. The next attempt sees the completed status, skips all work, and cleans up. Nothing is lost.
Cancellation Is a First-Class Feature, Not an Afterthought
Users cancel jobs. Networks drop. Budgets run out. A cancellation mechanism that does not actually stop the running work is not a cancellation mechanism — it is a lie with good UX.
There are two approaches to stopping a running task: forceful termination and cooperative cancellation.
Forceful termination sends a signal to the operating system process running the task.
SIGKILL ends the process immediately. SIGTERM requests a graceful shutdown — which
for a Celery worker means finishing the current task first. In practice, SIGTERM does
not cancel anything for long-running jobs. SIGKILL does, but it bypasses any
cleanup code you have written.
Cooperative cancellation is cleaner for most cases. The task periodically checks
a cancellation flag — in my case, a status field in MongoDB — and raises an
exception when it sees the cancelled state. This gives the task a chance to clean
up partial writes and update its status correctly.
The critical detail is the order of operations in the cancel endpoint. Mark the
job as cancelled in the database first, before sending SIGKILL or cleaning up
external stores. The task will see the cancelled status at its next checkpoint
and raise a controlled exception. Then SIGKILL is a safety net for when the task
is inside a native C extension (OCR, embedding model inference) where Python
checkpoints cannot fire.
For OCR specifically — which can process a document page by page — I added a cancellation check between each page. This means cancellation responds within one page's processing time, typically a few seconds, rather than waiting for the entire document to complete.
What I Would Tell Myself Before Building This
There are patterns here that apply to any AI processing pipeline, regardless of what you are processing or what technology you use.
Design for failure from the start, not after the first production incident. The naive pipeline works in testing because tests do not crash workers mid-write, do not have network timeouts between database calls, and do not send cancellation signals during OCR. Production does all of these things continuously.
Every retry must be safe to run twice. If your task is not idempotent, your retry logic is not retry logic — it is a bug accumulator. Deterministic IDs, unique constraints, and upsert semantics cost almost nothing to add upfront and save significant time to fix later.
Stage isolation is not premature optimization. Breaking a pipeline into separate tasks feels like extra work until OCR succeeds, embedding succeeds, and the database write fails for the fourth time and you watch the system re-run four minutes of model inference because you did not save the intermediate result.
The broker is not optional for anything that needs to survive a process restart. A task queue without a broker is a list of functions. The moment your server restarts, your work is gone. The moment you need to run on more than one machine, the whole system breaks. Add the broker from day one.
Time limits are a form of defensive programming. A task without a time limit makes implicit assumptions about external behavior — that the OCR library will not hang, that the embedding model will not deadlock, that the database connection will not block indefinitely. None of those assumptions are safe.
Progress tracking and task state are different things. Celery's result backend tracks whether a task succeeded or failed. Your users need to know what percentage of their document has been processed. These are separate concerns. Store progress in your own database and update it from within the task. Do not rely on polling the task state from the result backend for user-facing progress indicators.
The pipeline I run now is not dramatically more code than the original. The core logic — extract, embed, store — is exactly the same. What changed is the infrastructure around it: where files live, how failures propagate, what happens on retry, when cleanup runs, and how cancellation reaches a running process. None of it is algorithmically complex. All of it matters.
The patterns described here, message brokers, idempotent writes, stage isolation, deterministic IDs, cooperative cancellation, are not specific to any framework or language. They appear in every serious distributed processing system. The specific implementations differ; the underlying problems do not.
If you are building any system that runs expensive AI workloads in the background, document processing, audio transcription, image analysis, report generation, the question is not whether these failures will happen. It is whether your system will handle them correctly when they do.
Subscribe to Updates
Get notified about new projects and articles.
Comments
Loading comments...